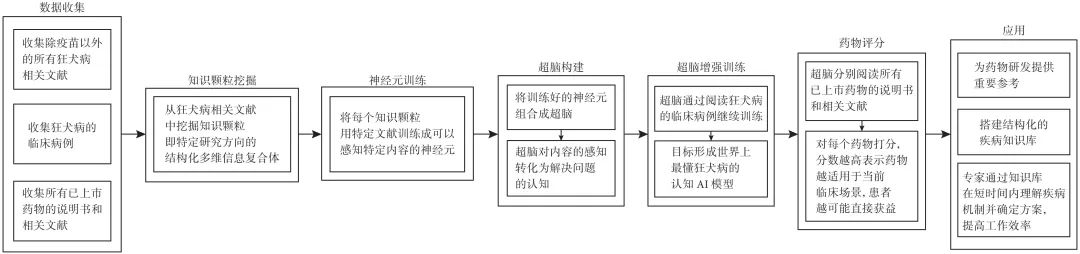
人工智能驱动的科学研究(AI4S)在药物研发与临床实践中的应用进展
人工智能驱动的科学研究(AI4S)在药物研发与临床实践中的应用进展在当今数字化时代,人工智能(artificial intelligence,AI)技术迅猛发展,尤其是生成式技术,如ChatGPT(chat generative pre-trained transformer),对人类生活的影响日益深远。
来自主题: AI技术研报
12700 点击 2024-08-19 17:38
 搜索
搜索
在当今数字化时代,人工智能(artificial intelligence,AI)技术迅猛发展,尤其是生成式技术,如ChatGPT(chat generative pre-trained transformer),对人类生活的影响日益深远。

过去几年间,Transformer 架构已经取得了巨大的成功,同时其也衍生出了大量变体,比如擅长处理视觉任务的 Vision Transformer(ViT)。本文要介绍的 Body Transformer(BoT) 则是非常适合机器人策略学习的 Transformer 变体。

一年前,谷歌最后一位 Transformer 论文作者 Llion Jones 离职创业,与前谷歌研究人员 David Ha共同创立人工智能公司 Sakana AI。Sakana AI 声称将创建一种基于自然启发智能的新型基础模型! 现在,Sakana AI 交上了自己的答卷。

Mamba 架构的大模型又一次向 Transformer 发起了挑战

2017 年,谷歌在论文《Attention is all you need》中提出了 Transformer,成为了深度学习领域的重大突破。该论文的引用数已经将近 13 万,后来的 GPT 家族所有模型也都是基于 Transformer 架构,可见其影响之广。 作为一种神经网络架构,Transformer 在从文本到视觉的多样任务中广受欢迎,尤其是在当前火热的 AI 聊天机器人领域。

七年前,论文《Attention is all you need》提出了 transformer 架构,颠覆了整个深度学习领域。
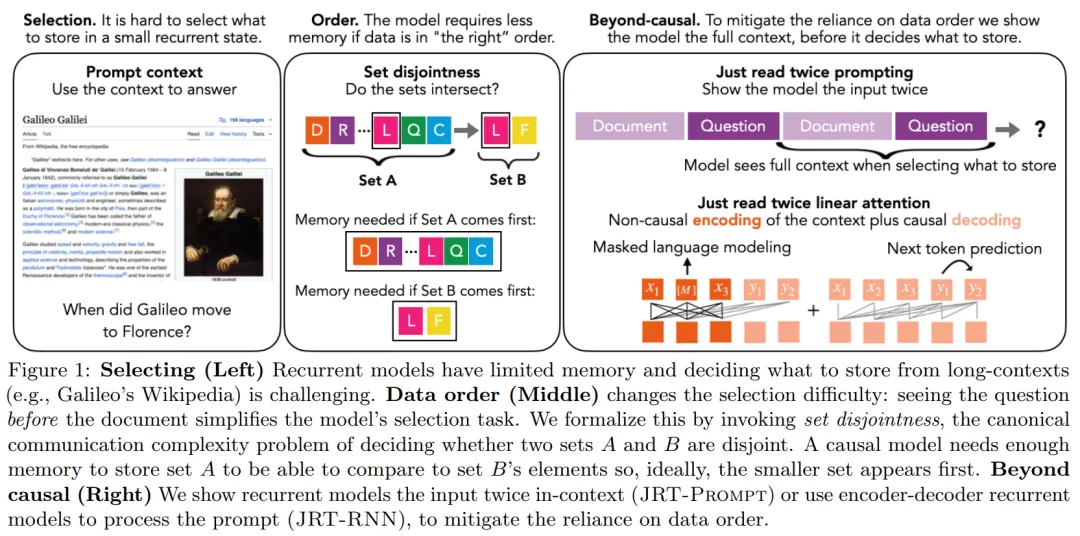
在当前 AI 领域,大语言模型采用的主流架构是 Transformer。不过,随着 RWKV、Mamba 等架构的陆续问世,出现了一个很明显的趋势:在语言建模困惑度方面与 Transformer 较量的循环大语言模型正在快速进入人们的视线。

自从大型 Transformer 模型逐渐成为各个领域的统一架构,微调就成为了将预训练大模型应用到下游任务的重要手段

释放进一步扩展 Transformer 的潜力,同时还可以保持计算效率。

上下文学习 (in-context learning, 简写为 ICL) 已经在很多 LLM 有关的应用中展现了强大的能力,但是对其理论的分析仍然比较有限。人们依然试图理解为什么基于 Transformer 架构的 LLM 可以展现出 ICL 的能力。